TYPES OF NOSQL DATABASE
Mainly, NoSQL database are of four types namely
Each key is unique and note that we can search only by using keys, not by values.
They are inefficient when you need to query or update only a part of the value.
Key-Value Store are used to implement shopping carts, user sessions, customer preferences etc.
It also supports aggregation like sum,average and other mathematics and set operations.
They are designed to store everyday data. MongoDB is the perfect example of Document oriented database.
- Key-Value Stores.(e.g. Riak, Redis, MemcacheDB)
- Column-family Stores.(e.g. HBase, Cassandra)
- Document-Oriented Database. (e.g. MongoDB, CouchDB)
- Graph Database. (e.g. Neo4J, HyperGraphDB, InfoGrid)
We will discuss each type one by one.
1. KEY-VALUE STORES
Key-Value Store is the simplest form of NoSQL database. It stores information as key and its value. These are similar to a dictionary or a hashtable. |
| Fig 1.a. Example of Key-Value Stores |
They are inefficient when you need to query or update only a part of the value.
Key-Value Store are used to implement shopping carts, user sessions, customer preferences etc.
2. COLUMN- FAMILY STORES
Since key-value stores do not allow updating only a part of value and we cannot fetch data by using values rather than key.
Column family databases store each column separately.
These databases are structured into group of related columns called Column-Families That is, each column family is a set of data that is often accessed together.
Data updating is very faster, it writes data faster.
Consider the example below for better understanding.
Figure 1.b shows that how a data is represented by using Relational Database. Now we will see that how it is represented by using Column Family Stores.
In this case, we cannot use queries like "age >20 and city="Delhi". "
It supports flexible schema, i.e. each data entry can have different attributes. Key-value stores and column-family stores have limited query support, whereas document-oriented databases provide rich querying options for storing, fetching, modifying and deleting data. This allows search and filter by any attribute value.These databases are structured into group of related columns called Column-Families That is, each column family is a set of data that is often accessed together.
Data updating is very faster, it writes data faster.
Consider the example below for better understanding.
 |
| Fig 1.b Data Representation by Relational Database |
Figure 1.b shows that how a data is represented by using Relational Database. Now we will see that how it is represented by using Column Family Stores.
 |
| Fig 1.c Data Representation by Column Family Stores. |
In this case, we cannot use queries like "age >20 and city="Delhi". "
3. DOCUMENT ORIENTED DATABASE
It also supports aggregation like sum,average and other mathematics and set operations.
 |
| Fig 1.d. Document Oriented Database |
They are designed to store everyday data. MongoDB is the perfect example of Document oriented database.
4. GRAPH DATABASE
All the NoSQL we had learnt so far is not suitable for data having high relation among them. But Graph databases are suited for data that are heavily interconnected through relationships.
Graphs do not need joins for querying. Graph databases use graph theory for traversal. These databases use simple nodes and edges to store and retrieve highly interrelated data. Graph traversals are much faster compared to SQL joins.
Graph databases provide Atomicity, Consistency, Isolation and Durability (similar to SQL).
We will try to make you learn with the help of an example. We all uses social media like Facebook, Instagram etc. So consider this small case. Fig 1.e. shows the representation of data by using Graph database.
If we represent this data by using SQL, then it would like as shown in fig 1.f. In SQL we have to maintain 2 tables and have to use the concept of foreign keys.
But there is difficulty in performing aggregations like max, sum etc.
Thanks for Reading.
Comment for any doubt or query!!!
By Aditya
Graphs do not need joins for querying. Graph databases use graph theory for traversal. These databases use simple nodes and edges to store and retrieve highly interrelated data. Graph traversals are much faster compared to SQL joins.
Graph databases provide Atomicity, Consistency, Isolation and Durability (similar to SQL).
We will try to make you learn with the help of an example. We all uses social media like Facebook, Instagram etc. So consider this small case. Fig 1.e. shows the representation of data by using Graph database.
 |
| Fig 1.e. Example of Graph Database |
If we represent this data by using SQL, then it would like as shown in fig 1.f. In SQL we have to maintain 2 tables and have to use the concept of foreign keys.
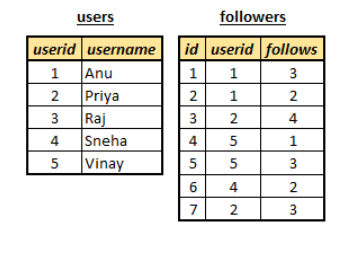 |
| Fig 1.f. Representation using SQL |
But there is difficulty in performing aggregations like max, sum etc.
 |
| Fig 1.g. Comparision |
Thanks for Reading.
Comment for any doubt or query!!!
By Aditya
Comments
Post a Comment